0. Pinecone
pinecone 은 chroma 와 마찬가지로 vector DB로서, chroma는 인메모리인 반면, Pinecone 은 클라우드를 활용한다.
따라서 LLM 서비스를 운영하는 서버를 이전할 때에도 무리 없이 데이터를 가져올 수 있다.
또한 일반적인 RDB 개념에서의 DB를 pinecone index라고 하는데, 5개까지 무료로 사용할 수 있다.
https://rusharp.tistory.com/186 에서 만들었던 코드 내용을 최대한 그대로 활용하여 진행해 보려고 한다.
1. 문서 가져오기

2. 문서 쪼개기

3. 임베딩 진행하기
여기부터 임베딩을 chroma DB 가 아닌, cloud 를 지원하는 pinecone DB 에 입력한다.
먼저 pinecone 홈페이지에 로그인한 뒤에 API_key 를 생성한다.
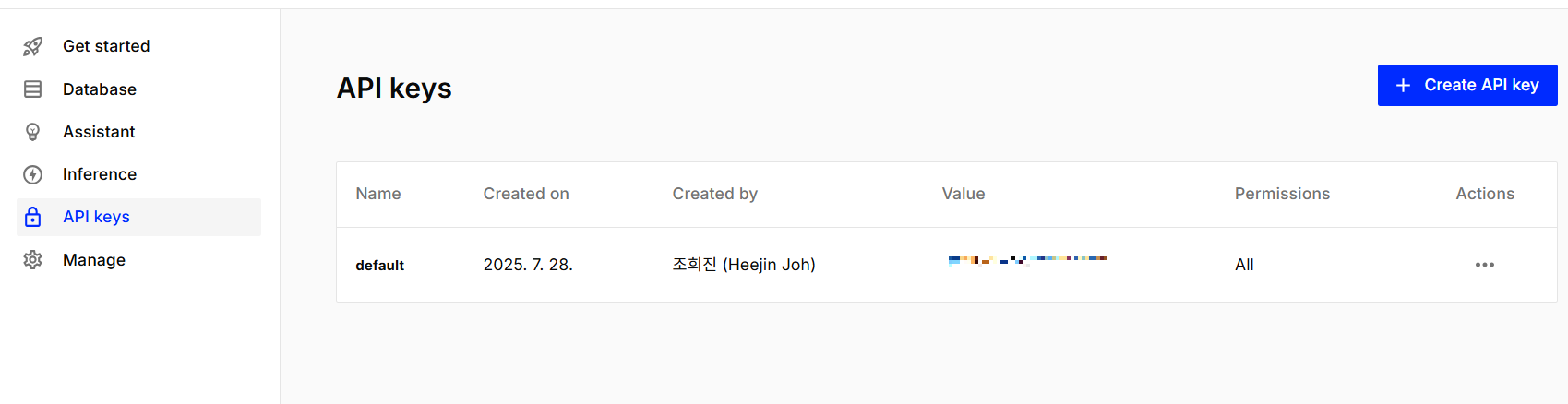
그다음에 Database / Indexes 에서 Create index 버튼을 눌러 index 를 생성하는데, 나는 아래와 같이 설정했다.

추가 설명을 하자면 dimension 은 벡터의 길이를 의미하는데, 임베딩 모델의 출력 크기와 반드시 일치해야 하고,
matric 은 유사도 계산 방식으로, 벡터끼리 얼마나 비슷한지를 비교할 때 어떤 방식으로 계산할지를 정하는 옵션이다.
추가로 유사도를 검색하는 방법은 Euclidean과, Dot product, cosine 이렇게 총 3가지 가 있다.
먼저 Euclidean 은 단어에 해당하는 점 사이의 거리를 재는 것이고, 거리가 짧을수록 가깝다.
Dot product는 Vector 의 list 를 동일한 번호끼리 곱하여 더한것으로, 숫자가 클수록 가깝다고 판단한다.
cosine 은 2 vector 사이의 각도를 계산하는 것으로, 각도가 작을수록 가깝다고 판단한다.
그리고 내가 dimension을 직접 입력한 이유는, embedding의 dimension과 동일해야 하기 때문이다.
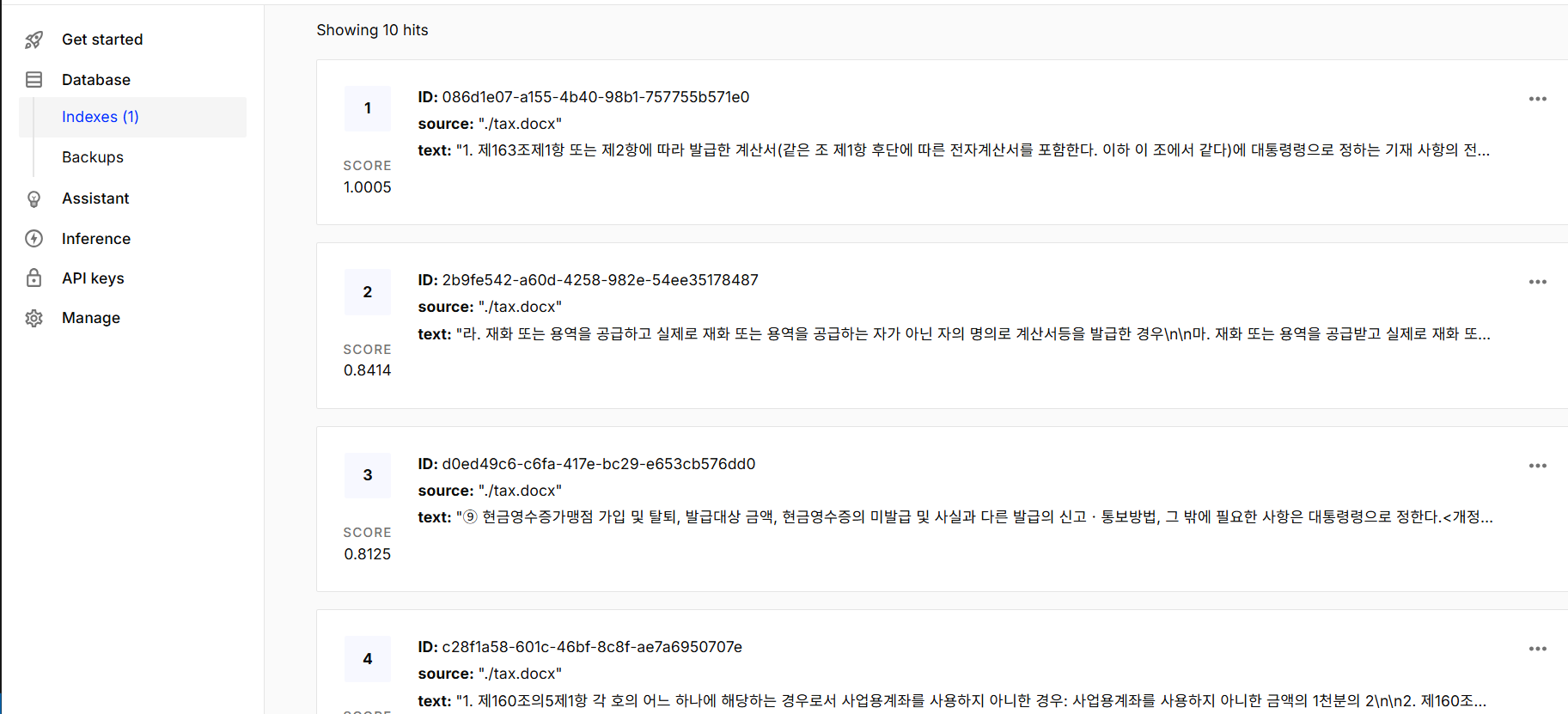
이제 아래와 같이 코드를 입력하면 스플릿된 document 들이 embedding 되어서 pinecone으로 들어간다.

이후 아래와 같이 값이 들어온 것을 확인할 수 있다.
4. 유사도 검색하기

5. LLM 질의
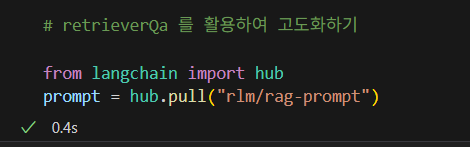
upstage 의 LLM을 Langchain에서 사용할 수 있도록 설정한 뒤에, LangChain Hub에서
RAG용 프롬프트 템플릿을 불러와 문서 + 질문 기반 응답 생성을 고도화한다.

마지막으로 위에서 작성한 질문에 대해 DB에서 관련 정보를 찾아와 AI가 답변을 추출한다.

이렇게 pinecone 으로 DB 를 수정해봤는데, 간편하게 실행할 수 있을 뿐 아니라 AWS를 활용하여,
기존 Chroma 의 메모리 기반 DB 의 불편한 점을 해결할 수 있다는 장점이 있다.
또한 LangChain 또한 다양하게 지원하고 있어 필요에 따라 많은 부분을 시도해볼 수 있다.
'RAG 을 활용하여 LLM 만들어보기' 카테고리의 다른 글
| Streamit 으로 chatbot 만들기 (2) | 2025.08.09 |
|---|---|
| Retrieval 효율 개선을 위한 데이터 전처리 (2) | 2025.08.04 |
| LangChain을 활용하지 않고 RAG 구성해보기 (2) | 2025.07.27 |
| RAG 을 활용한 LLM 만들기 필수 용어 및 흐름 (0) | 2025.07.21 |
| 환경설정 및 LangChain과 Chroma를 활용한 검증 및 RAG 구성해보기. (0) | 2025.07.20 |