이번에는 LangChain을 활용하지 않고 RAG를 구성해보려고 한다.
1. 문서 가져오기
먼저 문서를 가져오기 위해 pip install python-docx 이후, 아래와같이 paragraph 단위로 나누어 full_text 변수에 입력한다.

2. 문서 쪼개기
다음으로 tiktoken을 사용하여 문서를 토큰화한다. 내가 사용한 문서의 경우, 총 152700 토큰으로 구성되어 있다.
그러나 gpt-4o 는 128000 context window까지만 지원하기 때문에 토큰 개수를 조절해야 한다.
이 때문에 쪼개는것이 중요한데, token의 lenth 를 파악한 뒤 원하는 chunk size 로 쪼개고 문서로 반환한다.
https://platform.openai.com/docs/models/gpt-4o

참고로 아래와 같이 encoding 한 것을 다시 문서화(decoding) 함으로써 다시 문자 형태로 되돌릴 수도 있다..

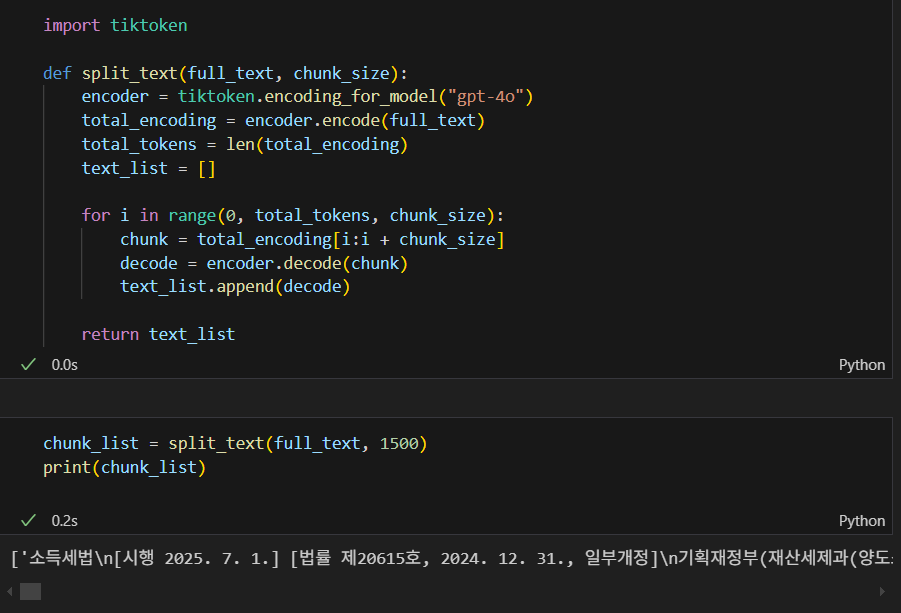
그렇다면 아까 인코딩한 문서를 원하는 청크 사이즈 크기로 문서의 처음부터 끝까지 나눌 수 있는데,
나는 각 1500 token으로 진행했고, 출력했을 때 원하는 텍스트가 하나씩 들어있다.
3. 임베딩 진행하기
LangChain chroma 에서 chroma를 가져오지 않고, chroma client 생성 후 collection을 만든다.
collection이 RDB 에서 table 과 같은 역할을 하고있으며, 아래와 같이 로컬에 vector DB 를 만들 수 있다.

다음으로는 Upstage 문자를 숫자로 변경하는 embedding model 을 불러온다.

`get_or_create_collection` 을 활용하여 컬렉션 생성 또는 가져온 뒤에 tax_collection에 넣어야 하는데
tax_collection 에 add 할 때, index를 같이 넣어야 하므로 chunk_list만큼 값을 늘려놓는다.


위와같이 두개의 리스트 길이가 동일한 상태에서 Chroma 컬렉션에 문서를 추가할 수 있다.

4. 유사도 검색하기
이미 query 에 embedding 이 되어있기 때문에, 아래와 같이 쿼리문을 전달하면 바로 답변을 받을 수 있다.

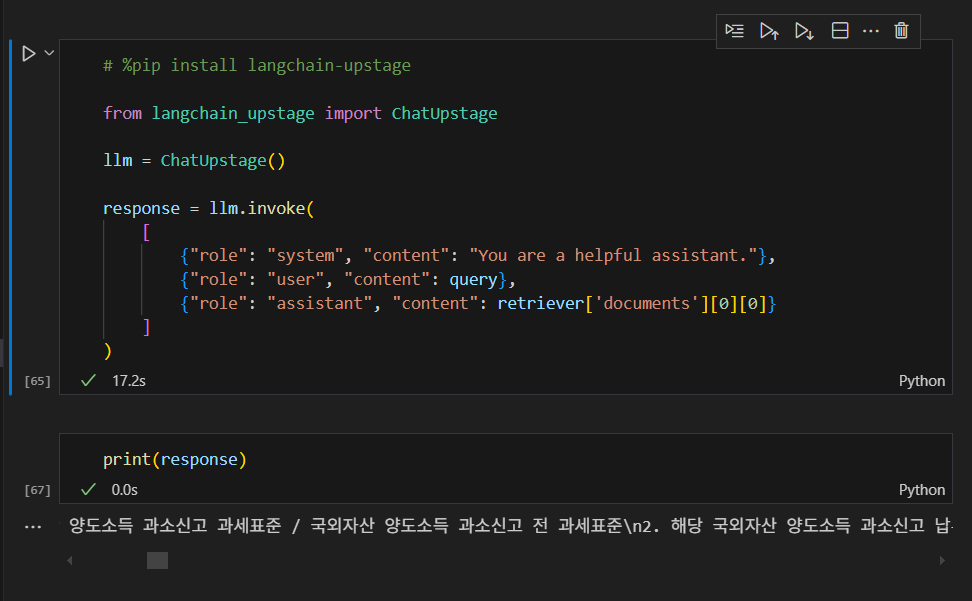
5. LLM 질의
아래와 같이 query를 날린 뒤 response 를 받을 수 있다. Langchain과 비교했을 때,
embedding, 검색, 질의를 한번에 관리할 수 있지만, 문서 parsing, chunking, embedding 등
관리할 패킷과 코드의 양이 많고 결과적으로는 서버가 불안정해서 memory chroma DB 가 사라진다.
반면 LangChain 에서는 자체적으로 관리되는 DB 가 많아서 별도 코드를 작성하지 않고,
Retriever 을 사용한 DB를 통해 다른걸로 변경하는 등 코드 작성이 훨씬 간편해진다는 장점이 있다.
'RAG 을 활용하여 LLM 만들어보기' 카테고리의 다른 글
| Retrieval 효율 개선을 위한 데이터 전처리 (2) | 2025.08.04 |
|---|---|
| Pinecone 과 LangChain을 활용한 Vector Database 변경 (2) | 2025.07.30 |
| RAG 을 활용한 LLM 만들기 필수 용어 및 흐름 (0) | 2025.07.21 |
| 환경설정 및 LangChain과 Chroma를 활용한 검증 및 RAG 구성해보기. (0) | 2025.07.20 |
| LLM에 관심을 가지게 된 계기와 필요 배경 지식 (4) | 2025.07.09 |