import requests
from bs4 import BeautifulSoup
url = "<https://rusharp.tistory.com/>"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
# tistory 전체 제목 목록 가져오기
# class 속성이 tit_post인 모든 "strong" element를 반환
titles = soup.find_all("strong", attrs={"class":"tit_post"})
print(len(titles))
for title in titles :
print(title.get_text())
- find_all : 속성이 일치하는 모든 element를 리스트 형태로 반환
## 가져온 값에 해당하는 정보 정리하기
items = soup.find_all("a", attrs={"class": "link_post"})
print(items)
print("-"*50)
# 첫번째값, 즉 홈으로 가는 값을 제거한다.
# 첫번째값은 타이틀이 없어서 "item.strong.get_text()"에러를 발생시킴
items.pop(0)
for item in items:
# 제목 정보 가져오기(soup내부 strong element의 text값)
title = item.strong.get_text()
# 링크 정보 가져오기(soup내부 href 속성값)
link = "<https://rusharp.tistory.com/>"+ item["href"]
# 카테고리 정보 가져오기
# (soup의 형제값 중 div element를 찾음 > div element의 a element의 text값.)
temp = item.find_next_sibling("div")
category = temp.a.get_text()
# 작성일 정보 가져오기(soup의 하위값 중 span값을 전부 찾은 뒤 2번째 element)
date = temp.find_all("span")[1].get_text()
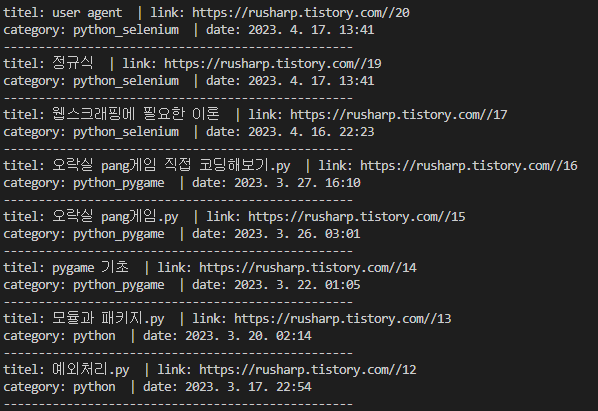
print("titel:",title," | link:",link," \\ncategory:",category," | date:",date,"")
print("-"*50)
# <https://www.crummy.com/software/BeautifulSoup/bs4/doc.ko/>
- https://www.crummy.com/software/BeautifulSoup/bs4/doc.ko/ 에서 더 자세한 정보 확인 가능.
뷰티플수프 문서 — 뷰티플수프 4.0.0 문서
find_all() 메쏘드는 태그의 후손들을 찾아서 지정한 여과기에 부합하면 모두 추출한다. 몇 가지 여과기에서 예제들을 제시했지만, 여기에 몇 가지 더 보여주겠다: 어떤 것은 익숙하지만, 다른 것
www.crummy.com
'python > python_selenium' 카테고리의 다른 글
| BeautifulSoup4 활용3 (0) | 2023.04.23 |
|---|---|
| BeautifulSoup4 활용2 (0) | 2023.04.22 |
| BeautifulSoup4 기본 (0) | 2023.04.18 |
| user agent (0) | 2023.04.17 |
| 정규식 (0) | 2023.04.17 |