1. HugginFace 의 동작 방식
HuggingFace 는 AI 모델과 데이터셋을 공유 및 실행할 수 있는 오픈 플랫폼을 의미한다.
Langchain 과 차이는 LangChain 은 chat openai 를 불러온 뒤에 모델을 그대로 chain 에 입력한다.
반면 HuggingFace 는 `텍스트 생성기`일 뿐, 채팅의 개념이 없어서 HugginFace model을 사용하는 것이 아닌,
토크나이저와 모델을 묶은 파이프라인을 만들고 그것을 LangChain 이 이해하는 Chat 인터페이스로 감싸서 쓰는 구조이다.
2. HuggingFace API 준비하기
HuggingFace 홈페이지에서 token을 발급받을 수 있다. 이 토큰을 HF_TOKEN 의 변수명에 입력한다.


3. HuggingFace 오픈소스 언어모델 활용하기
3-1. 패키지 설치
!pip install -q langchain transformers langchain-huggingface langchain-community langchain-core langchain-text-splitters bitsandbytes docx2txt langchain-chroma- langchain 관련: AI 애플리케이션 구축을 위한 프레임워크
- transformers : HuggingFace의 모델 사용을 위한 라이브러리
- bitsandbytes : 모델 양자화(용량 축소)를 위한 라이브러리
- docx2txt : Word 문서 처리용
- langchain-chroma : 벡터 저장소 관리
3-2. 기본 모델 로드
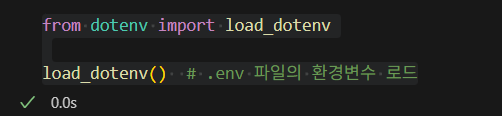
먼저 아래와 같이 dotenv 를 사용하여 .env 파일의 환경변수를 로드한다.
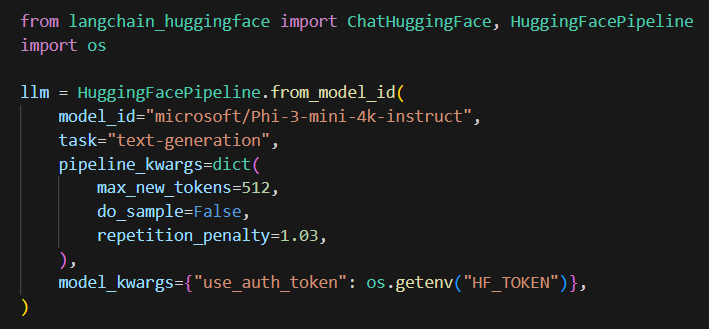
여기서 HuggingFacePipeline 을 생성하는데, 모델은 `microsoft/Phi-3-mini-4k-instruct` 를 사용한다.
text-generation 을 활용하여 텍스트 생성을 수행하고, max_new_tokens, do_sample, repetition_penalty 를 설정한다.
3-3. 챗 모델 인터페이스 생성 후 모델 사용

chat_model 에 모델을 래핑 후 모델에 "what is huggingface" 를 질문한 뒤 응답 내용을 출력한다.
다만 해당 모델은 양자화되지 않은 상태라서 모델이 너무 큰 상태라서 실행하는 데 시간이 오래 걸리게 된다.
3-4. 양자화하기
양자화란, 모델을 작게 만들어서 추론 시간을 빠르게 하는 기술을 의미한다.
나는 quantization(양자화) 를 활용하여 양자화를 진행하고, 양자화된 모델을 로드한다.
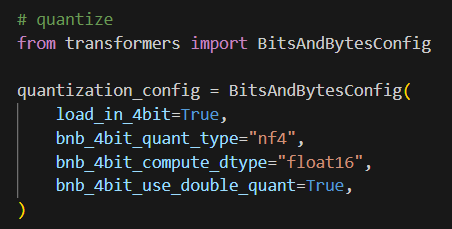
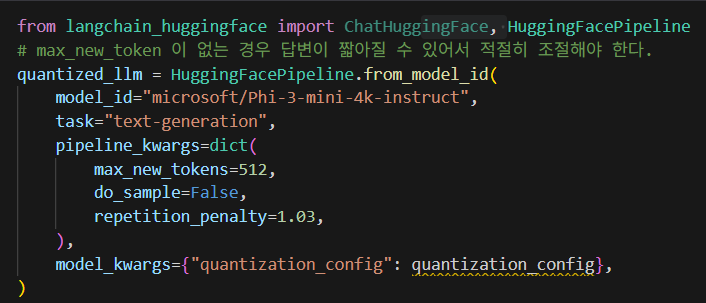
3-5. 양자화된 모델 사용
양자화된 모델을 사용하면 양자화되기 전에 비해서 훨씬 속도가 빨라진 것을 확인할 수 있다.

다음번에는 huggingface 오픈소스 언어모델을 활용한 RAG Pipeline 을 구성해볼 예정이다.
'RAG 을 활용하여 LLM 만들어보기' 카테고리의 다른 글
| HuggingFace 오픈소스 언어모델 활용한 RAG Pipeline 구성 (0) | 2025.09.10 |
|---|---|
| streamlit cloud 를 활용하여 서비스 배포하기 (0) | 2025.08.20 |
| Few Shot 을 활용한 답변 정확도 향상과 포맷 수정. (0) | 2025.08.18 |
| Chat History 추가와 Streaming 구현 (6) | 2025.08.17 |
| Streamit 으로 chatbot 만들기 (2) | 2025.08.09 |